Analysis of the construction steps of making an image recognition tool with TensorFlow
Editor's Note: Sara Robinson shared an interesting project on Medium where she developed an app that automatically recognizes Taylor Swift. This is quite similar to the Weili project we previously introduced. The tutorial is very detailed, and interested students can learn and build their own image recognition tools. This article has been authorized by the author, and the following is a compilation of the original text.
Note: Since TensorFlow does not have a Swift library at the time of writing this article, I used Swift to create an iOS app that sends prediction requests to my trained model.
Here is the app we created:
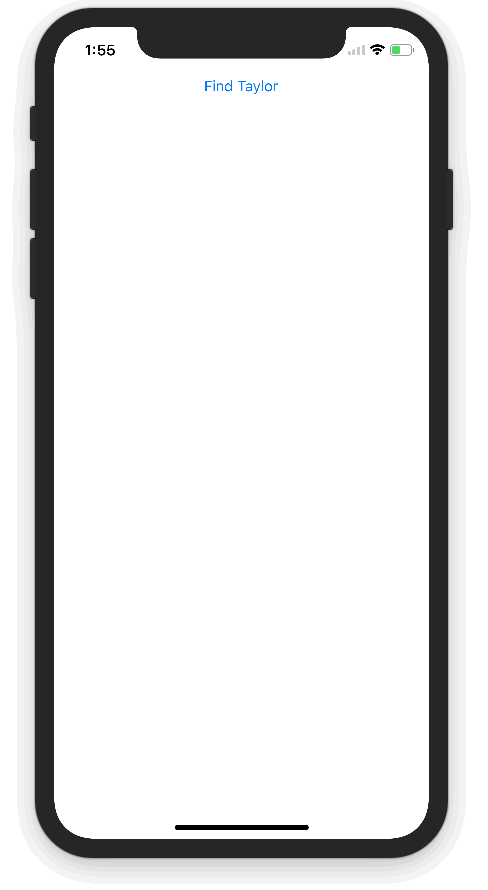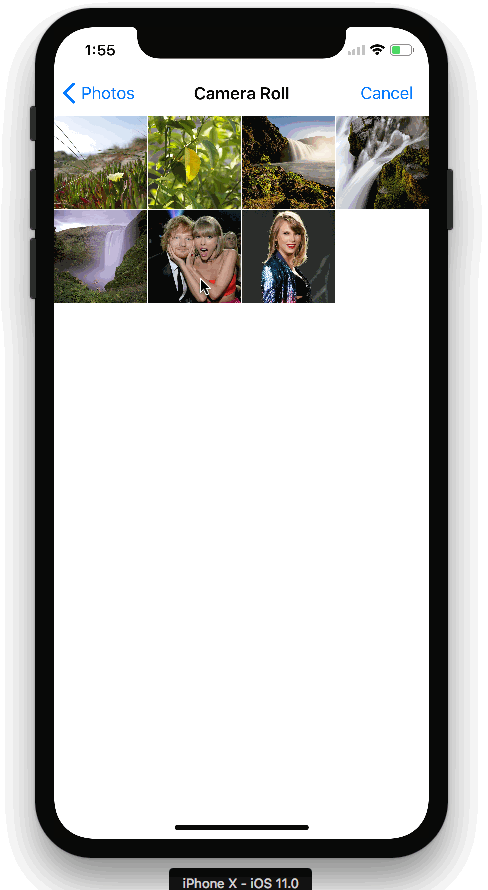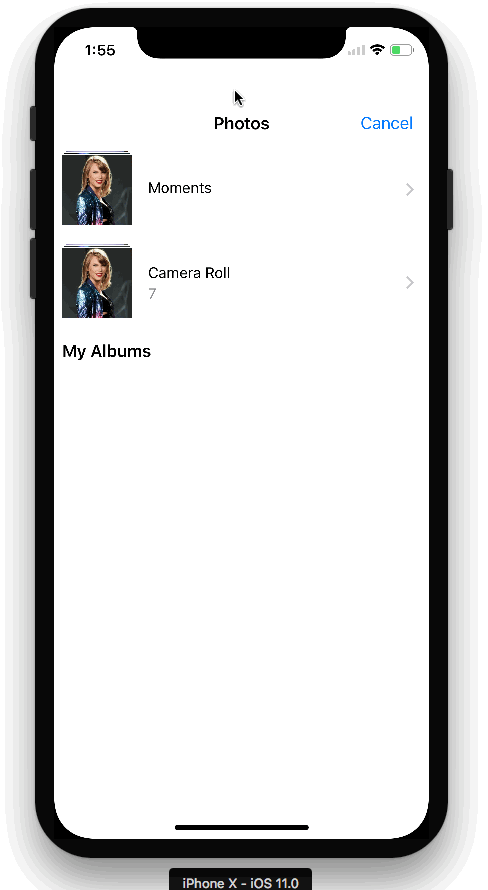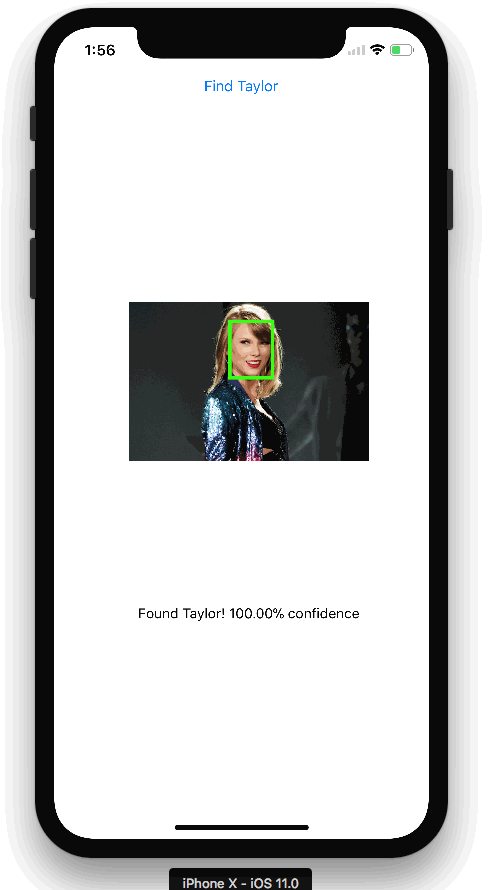
The TensorFlow Object Detection API allows you to identify the location of specific objects in an image, which can be applied to many interesting applications. As I often take pictures of people, I wanted to apply this technology to face recognition. It turned out that the model performed quite well! This is the Taylor Swift detector I created above.
This article will outline the steps involved in building the model, from collecting photos of Taylor Swift to training the model:
- Preprocess images by resizing, labeling, and splitting them into training and testing sets.
- Convert the images into Pascal VOC format.
- Convert the images into TFRecords files to comply with the object detection API.
- Use MobileNet to train the model on Google Cloud ML Engine.
- Export the trained model and deploy it to the ML Engine for serving.
- Build an iOS frontend and make prediction requests using Swift.
Here’s an architectural diagram showing how the different components fit together:
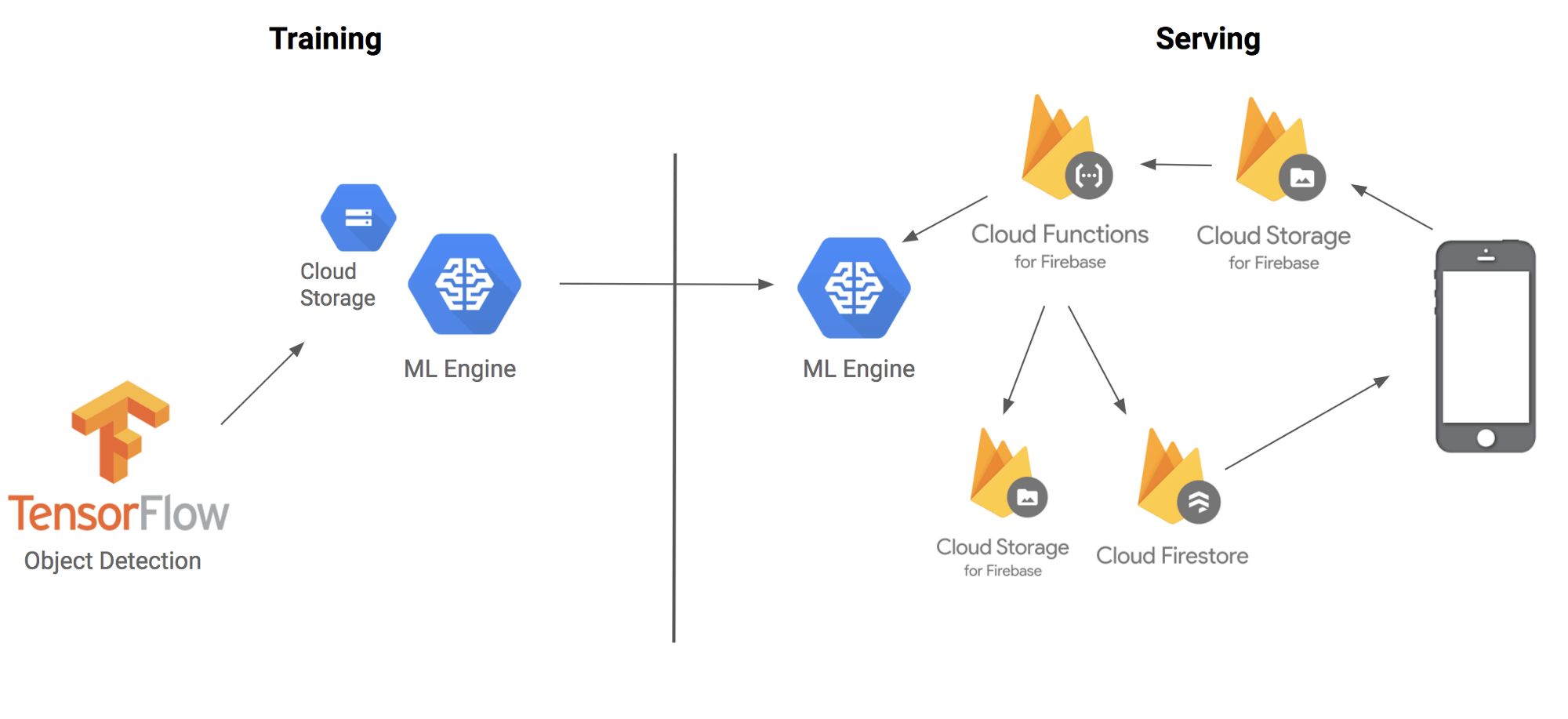
Before diving into the details, let’s briefly explain the techniques and terminology we’ll be using. The TensorFlow Object Detection API is a framework built on top of TensorFlow that identifies specific objects in an image. For example, you can train it using a large number of cat images. Once trained, you can input an image of a cat, and it will output a list of bounding boxes indicating where the cat is located. While it’s called an API, think of it more as a convenient tool for deploying machine learning models.
However, training a model to recognize objects in images is a time-consuming and labor-intensive process. One of the coolest aspects of object detection is its support for transfer learning using five pre-trained models. Transfer learning works by leveraging knowledge gained from one task to improve performance on another. For instance, when children learn to recognize cats, they are exposed to many examples and receive immediate feedback. When they later learn to recognize dogs, they don’t need to start from scratch; they can use the same cognitive processes but apply them to a new object. This is the essence of transfer learning.
In my case, I didn’t have time to collect and label thousands of Taylor Swift images, so I used transfer learning by modifying the last few layers of a model that was trained on millions of images.
Step 1: Preprocessing the Images
Thanks to Dat Tran’s blog post on the Raccoon Detector, I had a good starting point. First, I downloaded 200 images of Taylor Swift from Google Images using a Chrome plugin called Fatkun Batch Download Image. Before labeling, I divided the images into two categories: training and testing. I also wrote a script to resize the images (available on GitHub) to ensure that the width of each image did not exceed 600 pixels.
Since the detector needs to locate objects within an image, you can’t directly use the image and labels as training data. You must draw bounding boxes around the object and label them. In our dataset, we only needed one label: "tswift."
I used LabelImg, a Python-based tool, to draw these bounding boxes. After labeling, LabelImg generated XML files that described the positions of the objects in the images. Here's an example of what the XML file looked like:
```xml
DesktopTswift.jpg/Desktop/tswift.jpgUnknown100066730
```
Now that I had labeled images, I needed to convert them into a format that TensorFlow accepts—TFRecords. I followed a guide on GitHub and ran a script from the `tensorflow/models/research` directory with the following parameters:
```bash
python convert_labels_to_tfrecords.py \
--output_path=train.record \
--images_dir=path/to/your/training/images/ \
--labels_dir=path/to/training/label/xml/
```
I repeated this process for both the training and test datasets.
Step 2: Training the Detector
Training the model on a laptop would take too long and consume too many resources. To speed things up, I decided to use the cloud. Google Cloud ML Engine allowed me to run multiple training jobs efficiently and complete the work in just a few hours.
I created a project in the Google Cloud Console and enabled the Cloud ML Engine. Then, I set up a cloud storage bucket to store all the model resources. I uploaded the training and test TFRecord files to the `/data` subdirectory of the bucket.
Next, I added a `pbtxt` file that maps labels to integer IDs. Since we only had one label ("tswift"), the file was simple:
```text
item {
id: 1
name: 'tswift'
}
```
I also downloaded the MobileNet checkpoint for transfer learning. MobileNet is a lightweight model optimized for mobile devices, and even though I wouldn't train it directly on a mobile device, it would allow faster predictions.
After setting up all the necessary files, I created a configuration file that told the training script where to find the model checkpoints, label mappings, and training data. I updated the placeholder paths to point to my cloud storage bucket and configured several hyperparameters for the model.
Once everything was ready, I submitted the training job using the `gcloud` command:
```bash
gcloud ml-engine jobs submit training ${YOUR_TRAINING_JOB_NAME} \
--job-dir=${YOUR_GCS_BUCKET}/train \
--packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz \
--module-name object_detection.train \
--region us-central1 \
--config object_detection/samples/cloud/cloud.yml \
--runtime-version=1.4 \
-- \
--train_dir=${YOUR_GCS_BUCKET}/train \
--pipeline_config_path=${YOUR_GCS_BUCKET}/data/ssd_mobilenet_v1_coco.config
```
I also started an evaluation job to assess the model's accuracy using unseen data:
```bash
gcloud ml-engine jobs submit training ${YOUR_EVAL_JOB_NAME} \
--job-dir=${YOUR_GCS_BUCKET}/train \
--packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz \
--module-name object_detection.eval \
--region us-central1 \
--scale-tier BASIC_GPU \
--runtime-version=1.4 \
-- \
--checkpoint_dir=${YOUR_GCS_BUCKET}/train \
--eval_dir=${YOUR_GCS_BUCKET}/eval \
--pipeline_config_path=${YOUR_GCS_BUCKET}/data/ssd_mobilenet_v1_coco.config
```
You can check the status of your jobs in the Cloud Console under the Jobs section.
Step 3: Deploying the Model
To deploy the model to the ML Engine, I converted the model checkpoint to a Protobuf file. I downloaded the latest checkpoint files from the training bucket and used the `export_inference_graph.py` script to convert them into a format compatible with the ML Engine.
After exporting the model, I uploaded the `saved_model.pb` file to the cloud storage bucket. Finally, I created a model in the ML Engine and deployed the first version of the model:
```bash
gcloud ml-engine models create tswift_detector
gcloud ml-engine versions create v1 --model=tswift_detector --origin=gs://${YOUR_GCS_BUCKET}/data --runtime-version=1.4
```
Once the model was deployed, I used the ML Engine's online prediction API to generate predictions for new images.
Step 4: Building the Predictive Client with Firebase and Swift
I built an iOS client in Swift that sends prediction requests to the model. The app uploads an image to cloud storage, triggers a Firebase function, which then makes a prediction request via Node.js, and saves the predicted image and data back to cloud storage and Firebase.
In the Swift code, I added a button that lets users select an image from their device. When an image is selected, it is uploaded to cloud storage:
```swift
let firestore = Firestore.firestore()
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) {
let imageURL = info[UIImagePickerControllerImageURL] as? URL
let imageName = imageURL?.lastPathComponent
let storageRef = storage.reference().child("images").child(imageName!)
storageRef.putFile(from: imageURL!, metadata: nil) { metadata, error in
if let error = error {
print(error)
} else {
print("Photo uploaded successfully!")
// TODO: create a listener for the image's prediction data in Firestore
}
}
}
```
I also wrote a Firebase function that is triggered when an image is uploaded. The function uses the ML Engine API to make predictions and draws bounding boxes around detected faces. The results are saved to Firestore, and the iOS app listens for updates to display the predicted image and confidence score.
Finally, the iOS app monitors Firestore for changes and displays the predicted image along with the confidence level.
All right! Now we have a working Taylor Swift detector. Keep in mind that the model was trained on only 140 images, so the accuracy may not be perfect and could sometimes misidentify other faces as Taylor Swift. However, with more data, the model can be improved and eventually published to the App Store.